Voorspellend onderhoud in zes stappen
Binnen de industrie zijn we afhankelijk van de technische beschikbaarheid van veel componenten; machines, systemen en installaties om bijvoorbeeld te transporteren, staal te produceren en gas te leveren. Traditioneel zien we dat zowel Stork als andere bedrijven hun klanten hebben geholpen productielijnen draaiende te houden, volgens een in de industrie bewezen, op betrouwbaarheid gebaseerde onderhoudsmethode (RCM, Reliability Centered Maintenance). Dit gebeurt door een combinatie van onderhoudsmethoden: reactief gebaseerd onderhoud (RBM), op tijd gebaseerd onderhoud (TBM) en conditie gebaseerd onderhoud (CBM). Een nadeel daarvan was dat deze uitgaat van de gemiddelde tijd tussen falen (MTBF) en de veronderstelling dat het faalpatroon in de loop van de tijd toeneemt. Dit betekent dat vanwege de variatie in MTBF, een op conditie gebaseerde strategie of een op tijd gebaseerde strategie, ertoe kan leiden dat een onderdeel vaker faalt dan men zou willen; resulterend in verloren productietijd en opbrengsten en potentieel onnodig vervangen onderdelen.
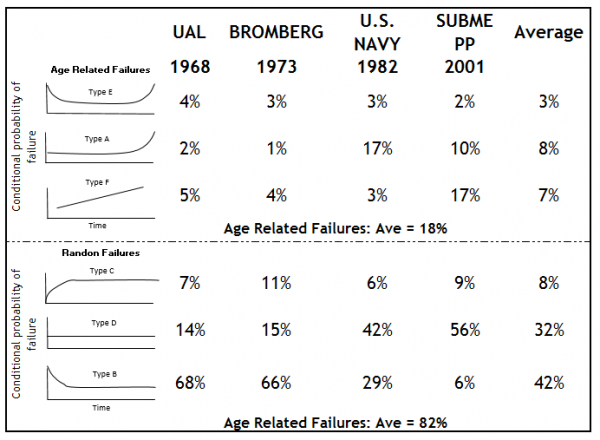
Een ander scenario doet zich voor wanneer degradatie wordt gedetecteerd door onderhoudsinspecties uit te voeren, wat resulteert in een toename van het aantal manuren en soms zelfs een hogere werklast dan in een run-to-failure scenario. Aangezien slechts 18% van de fouten leeftijd-gerelateerd is en 82% een willekeurig faalpatroon heeft (NASA/US Navy, 2008, zie figuur 1), biedt RCM geen complete oplossing voor het optimaliseren van onderhoud.
Figuur 1
Dit is waar het belang van voorspellend onderhoud of predictive maintenance duidelijk wordt. Het is een middel om de technische beschikbaarheid van een asset te optimaliseren door onderhoudsparameters zoals frequentie en de lopende onderhoudsstrategie te beïnvloeden. Methoden en technieken voor voorspellend onderhoud zijn dus ontworpen om de conditie (gezondheid) van in gebruik zijnde assets te helpen bepalen: wanneer is onderhoud nodig?
Hoe bereik je dit?
De vraag is dan hoe je voorspellend onderhoud realiseert. Eerst voegen we sensoren toe aan het systeem dat gegevens over de operationele prestaties zal controleren en verzamelen. Bij Stork zien we dat veel bedrijven al over aanzienlijke hoeveelheden gegevens beschikken die worden gebruikt om de processen te sturen. Nog beter is dat deze historische gegevens vaak al jarenlang in hun historian systemen zijn opgeslagen. Wij adviseren klanten om deze gegevens actief te gaan gebruiken bij het voorspellen van de resterende levensduur van assets. Doorgaans omvatten gegevens voor voorspellend onderhoud een tijdstempel, een reeks sensormetingen verzameld op hetzelfde moment met tijdstempel en apparaat-identificaties.
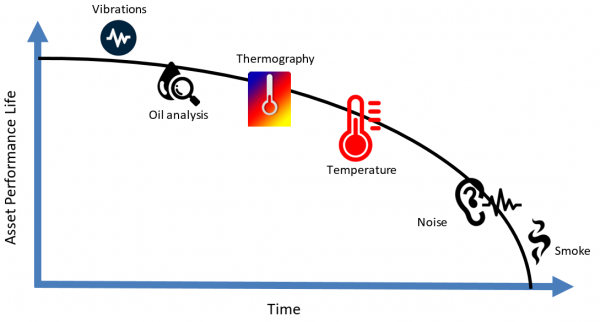
De pf-curve in figuur 2 hieronder illustreert dat een asset op het tijdstip t = 0 een bepaalde prestatie levert en dat naarmate de tijd verstrijkt, deze prestatie afneemt. Dit kan te wijten zijn aan gebruik, veroudering, slijtage, omgeving en nog veel meer factoren.
Figuur 2
Verder illustreert figuur 2 dat u gedurende de levensduur van een asset anomaliecategorieën kunt opstellen uit de verschillende soorten gegevens als de asset in de loop van de tijd degradeert. De eerste indicatie van degradatie kan voortkomen uit trillingsmetingen en olie-analyse. Daarna zal de asset hogere (dan normale) temperatuurmetingen vertonen. Het kan moeilijk zijn vast te stellen wanneer een faalmodus precies is begonnen, maar we kunnen op zoek gaan naar tekenen van verval om het probleem aan te pakken voordat de asset faalt. Daarom is het belangrijk om het gedrag van de sensormetingen voor elke storingsmodus van elk asset te begrijpen.
Uit ervaring weten we dat classificatie- en clustering algoritmen het best passen bij de toepassing voor voorspellend onderhoud. Met deze algoritmen kunt u historische gegevens (asset gedrag) categoriseren in vooraf gedefinieerde classificatie- / clustergroepen. De combinatie van een verhoging van de temperatuur en een licht stijgende waarde van de trillingsmeting resulteert bijvoorbeeld in een categorielabel zoals "Een week voor falen". Nogmaals, de categorisering van gegevens (labeling) is een belangrijk onderdeel van predictief onderhoud. Deze labels worden bepaald voor elk individueel geval (elke combinatie van asset en faalmodus) en kunnen variëren van een binair label zoals 'Goede prestaties' of 'Slechte prestaties' om uiteindelijk een meer doorlopende classificatie te krijgen voor de resterende gebruiksduur '30 dagen', ' 29 dagen ", etc. Algoritmen die kunnen worden gebruikt voor classificatie zijn bijvoorbeeld (lineaire) Support Vector Machine, Naïve Bayes, KNeighbors en logistic regressie en voor clustering zijn dit KMean, MeanShift en SpectralCLustering. Welke algoritmen u kiest voor de beste fit hangt af van de steekproefomvang, het gegevenstype (gelabeld, hoeveelheid of tekstgegevens) en diepgaande kennis van de faalwijzen van de asset.
Zes-stappenmodel voor asset performance managment
Stork heeft een zes-stappenmodel ontwikkeld dat onze klanten helpt bij het kiezen van het juiste algoritme en de juiste implementatiemethode in uw organisatie.
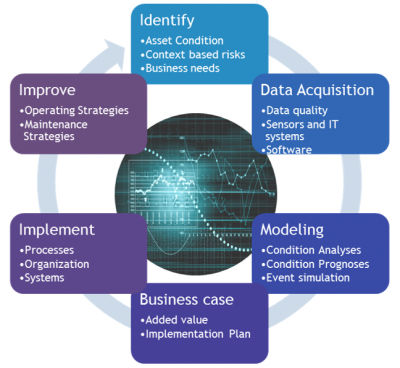
De eerste stap omvat het begrijpen van de functionaliteiten van de asset en de faalwijzen. Storingsgegevens worden uit uw CMMS-systeem (Computerized Maintenance Management System) gehaald en procesgegevens worden uit het handboek van de fabrikant gehaald. Het resultaat van deze fase bestaat uit een diepgaand inzicht in de dominante faalmodus en de (financiële) impact ervan op de organisatie.
De tweede stap omvat het selecteren van historische gegevens die gegevensstromen of patronen bevatten die kunnen worden gelabeld als "goede prestaties" of als "slechte prestaties". Omdat algoritmen alleen patronen kunnen leren die al in de gegevens aanwezig zijn, moet de doel-set voldoende groot zijn om deze patronen te bevatten, terwijl ze toch beknopt genoeg blijven om binnen een aanvaardbare tijdsbestek te worden gevonden. De gegevenssets worden vaak opgeslagen in verschillende databases die aanvullende integratie vereisen. Naast de hoeveelheid wordt ook de kwaliteit van de gegevens tijdens deze fase beoordeeld. Alle gegevenssets moeten dezelfde tijdstempel hebben om meerdere sensoren voor één voorspelling te kunnen gebruiken. Vervolgens wordt voor ontbrekende gegevens interpolatie toegepast en worden ruisgegevens verwijderd.
De derde stap (modellering) is het extraheren van patronen uit de gegevens. Dit omvat de selectie en toepassing van geschikte (wiskundige) algoritmen en de ontwikkeling van een model dat het patroon beschrijft. Deze stap gaat vaak gepaard met 'traditionele' statistische analyse, gegevensvisualisatie en simulatie van historische gegevens (ontwikkeling van demo-versie).
In de vierde stap wordt een businesscase ontwikkeld om de voordelen van het voorspellen van een faalmodus hard te maken. De kosten van het schrijven van een algoritme en real-time monitoring worden vergeleken met de financiële voordelen. Potentiële besparingen kunnen worden onderscheiden in twee hoofdvormen: (1) Productie downtime voorkomen of minimaliseren en (2) De periodieke onderhoudswerkzaamheden optimaliseren. Andere voordelen zijn bijvoorbeeld de kapitalisatie van kennis, verlenging van de levensduur van assets, evenals verbeteringen op het gebied van gezondheid, veiligheid en milieu. Deze 'andere' voordelen zijn niet altijd aanwezig en als ze dat wel zijn, kan het moeilijk zijn ze te kwantificeren.
Als de businesscase een positief resultaat heeft, gaat u door naar de implementatiefase (stap 5) door de acties uit te voeren die in de vorige fasen zijn gedefinieerd. Het resultaat van deze fase is dat de organisatie in staat is om de informatie die het model levert te gebruiken om uiteindelijk onderhoudsintervallen en werkprocessen aan te passen.
Ten slotte moet, als zesde en laatste stap, de verbetercyclus worden gesloten. Tijdens de operationele fase begint het algoritme een zelflerend model te zijn als gevolg van voortdurende verbetering door de Data Scientist. Extra foutpatronen worden continu aan het algoritme toegevoegd.
Vanwege de grote hoeveelheid reeds beschikbare gegevens en de mogelijkheid om eenvoudig complexe algoritmen te ontwikkelen, is het nu de tijd om dit te gebruiken voor het voorspellen van de gezondheid van onze belangrijkste assets. De ontwikkeling van effectieve algoritmen voor voorspellend onderhoud kost tijd en betalen van leergeld is onvermijdelijk. Ik ben er echter van overtuigd dat de totale voordelen ruim opwegen tegen de initiële investering.
Type I en type II fouten in voorspellend onderhoud
Binnen de statistiek kunnen twee typen fouten optreden. De type I-fout is de onjuiste afwijzing van een correcte nulhypothese (ook bekend als een "fout positieve" bevinding), terwijl een type II-fout ten onrechte een foutieve nulhypothese (ook bekend als een "fout negatieve" bevinding) onderschrijft.
Binnen voorspellend onderhoud is dit ook aan de orde. De fout die overeenkomt met de type I-fout, is dat u een asset detecteert die niet werkt, maar dat de prestaties van de asset eigenlijk goed (gezond) zijn. Deze fout geeft een onterechte rechtvaardiging om te investeren in voorspellend onderhoud. Dit zal ertoe leiden dat een technicus wordt gemobiliseerd om de asset te controleren, terwijl het in goede staat verkeert, of erger nog, u vervangt componenten van een gezonde asset. Daarom ben ik van mening dat de onderhouds- en reliability engineer van het Industry 4.0 tijdperk zich expert mogen noemen wanneer ze morgen ontdekken waarom de dingen die ze gisteren voorspelden niet zijn gebeurd.
De type II-fout heeft meer gevolgen met betrekking tot kosten. In dit geval is er een fout opgetreden, maar is deze niet voorspeld. Beide fouten worden voorkomen door een verbeteringsproces in te richten (stap 6 van ons APM-model). Dit betekent dat algoritmen voortdurend nieuwe faalpatronen moeten leren totdat het algoritme slim genoeg is om 100% van de falende assets correct te voorspellen.